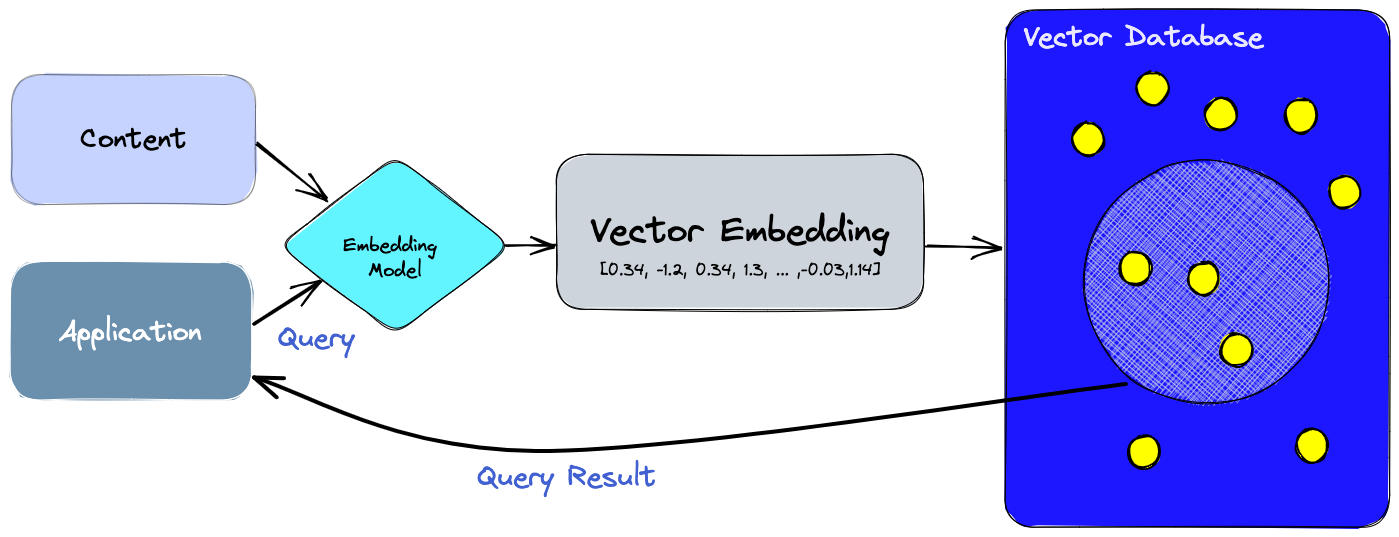
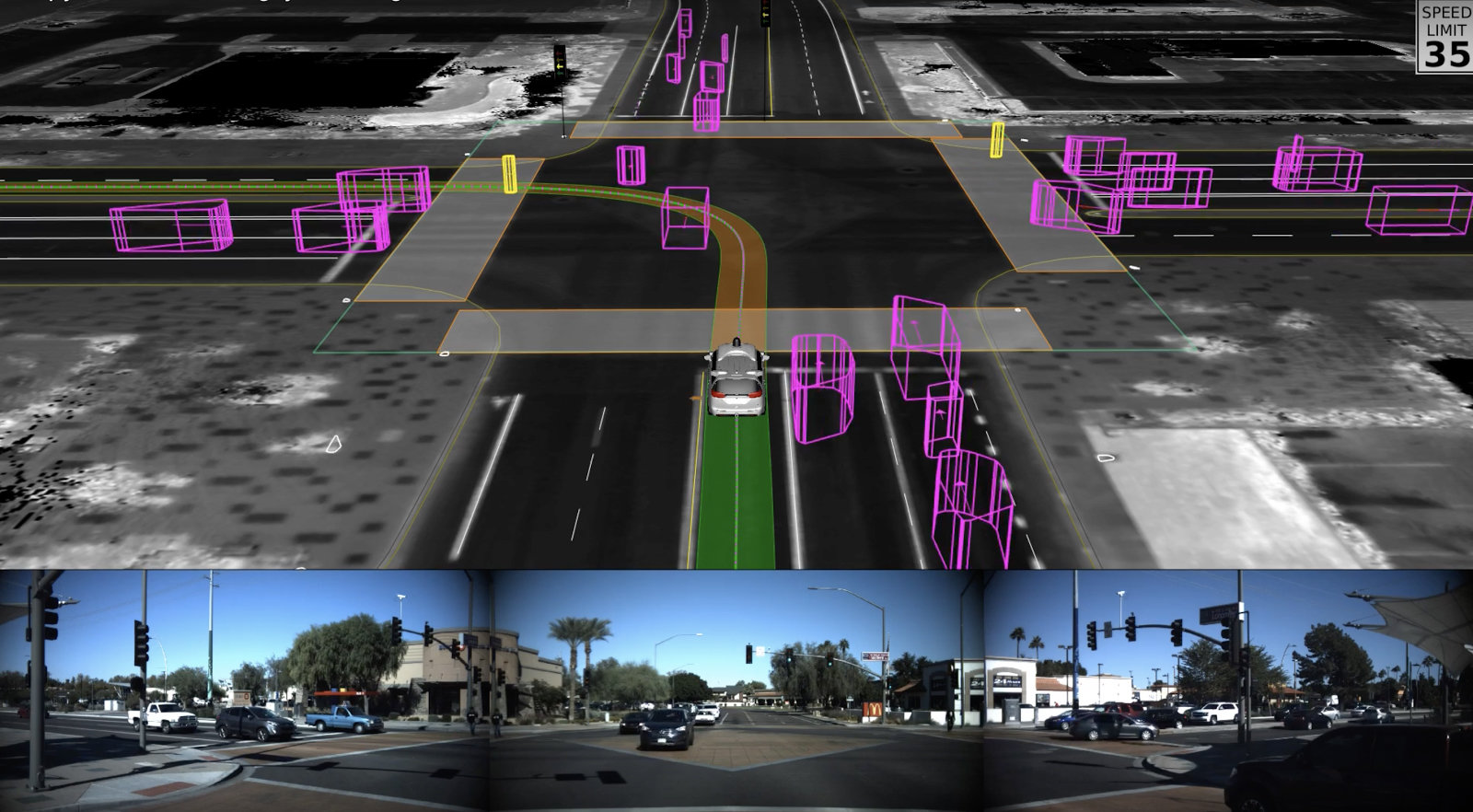
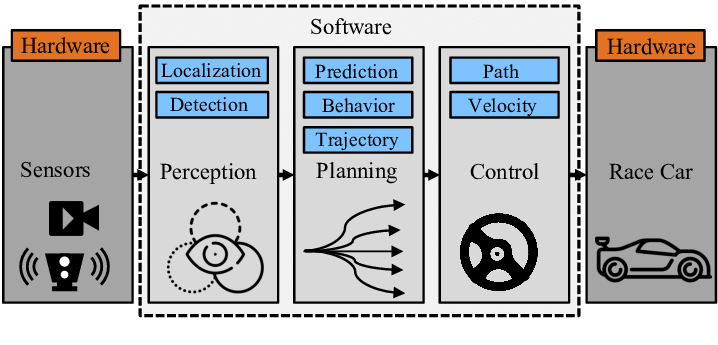
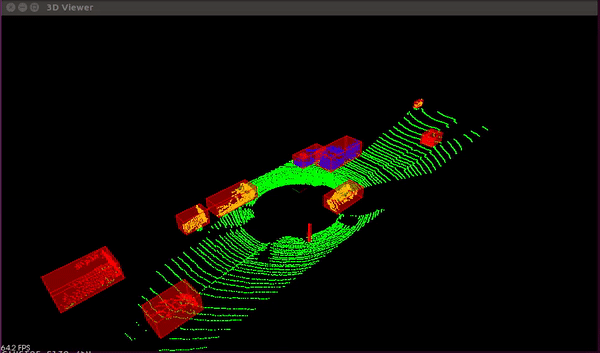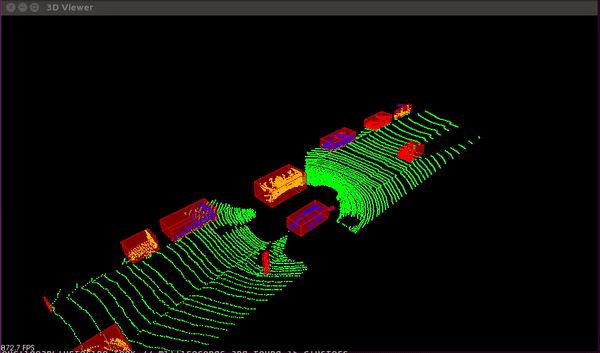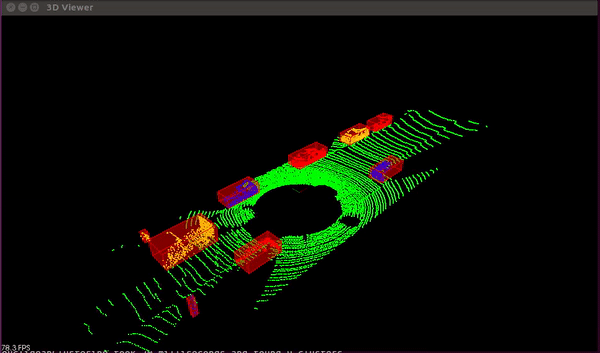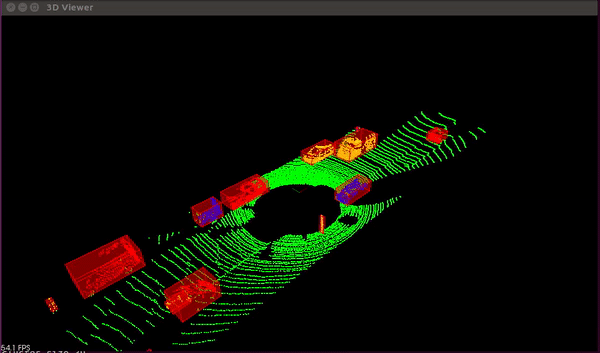
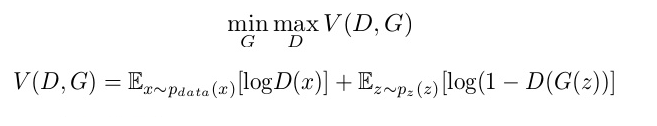Introduction:
Numerous facets of human existence, both personal and professional, have undergone radical change as a result of the technology's quick development, widespread application, and adoption. Enterprise-grade solutions built on artificial intelligence (AI) and machine learning (ML) are being used more and more to automate repetitive processes with the goal of assisting and augmenting human labor so that enterprises can do more throughout the workday.AI Copilot is one such recent advancement in this broad field.
An AI Copilot: What Is It?
AI copilots assist humans with a variety of duties, just way copilots in the aviation sector assist pilots with navigation and sophisticated aircraft systems management. They employ natural language processing (NLP) and machine learning to interpret user inputs, offer insights, or carry out activities either fully autonomously or in conjunction with human equivalents. These digital assistants are widely used in a variety of contexts, from writing code and virtual correspondence to serving as the foundation for specialized tools that improve efficiency and productivity.
Why Do We Need Enterprise Copilots?
The enormous amount of data that organizations generate today and the complexity that goes along with it provide some issues. It can be challenging to analyze this data, particularly when businesses require real-time insights supported by evidence to make wise decisions. In these situations, non-technical individuals can access data with the aid of AI-based solutions. Copilots democratize data access inside the company by comprehending natural language inputs and crafting unique queries to organize and structure data for rapid, insightful analysis.
How Do Copilot AIs Operate?
These systems use cutting-edge technology such as natural language processing (NLP), machine learning, application programming interface (API) integration, fast engineering, and strong data privacy policies. When combined, these elements provide copilots the ability to comprehend and efficiently assist with intricate business activities.
For example, natural language processing (NLP) is essential in the customer service industry to understand and respond to consumer inquiries, thus streamlining the help process.
If every customer support executive is busy, a trained chatbot can be used to respond to the customer's questions until an agent is available.
Large language models (LLMs) are integrated into these systems to enhance them and enable a wide range of applications. AI systems can understand human language and respond to user inquiries thanks to NLP, and ML algorithms and LLMs work together to understand user requirements and provide pertinent recommendations that have been fine-tuned via training on large amounts of textual data.
As an iterative process that changes in response to user inputs, prompt engineering is a critical element in improving user prompts to get accurate responses from the GenAI model.
AI Copilots' Benefits for Businesses
In order to achieve widespread productivity improvements of 10% to 20% throughout an organization, generative AI tools are a crucial part of AI copilots, according to research from the Boston Consulting Group. They restructure business operations and procedures with the potential to increase productivity and effectiveness in domains such as software development, marketing, and customer support by 30% to 50%.
The objective examination of past and present data provides vital information about possible hazards, allowing companies to create more efficient risk-reduction plans. This proactive strategy fosters a unified organizational vision and goes beyond conventional risk management. Processing large amounts of data opens up new avenues for product creation, market expansion, and operational enhancements, which promotes ongoing innovation.
Companies struggle to forecast needs and comprehend human behavior. Big data analysis is a skill that copilots can use to enhance consumer experiences and cultivate loyalty. Seasonal pattern analysis and real-time sentiment analysis improve consumer interactions and revolutionize every connection.
The implementation of these solutions also results in a large cost savings.They reduce operating costs, free up human resources for key responsibilities, and reduce errors by automating repetitive processes. These tools assist companies in their quest for sustainability by balancing ecological responsibility and operational efficiency through improved resource management and operations. AI copilots for manufacturing, for example, can anticipate the need for machine maintenance, cutting downtime and prolonging equipment life to lessen environmental impact.
How to Integrate AI Copilot with Large-Scale Data
Selecting the best AI Copilot necessitates carefully weighing a number of variables in order to guarantee peak performance and easy integration. Any firm must make a key decision when choosing a system, as it can have a big impact on the organization's capacity to extract useful insights from data.
Quantity and Intricacy
Numerous elements need to be taken into account, including the quantity of the datasets, the diversity of the data sources, and the degree of format and data structure complexity. An efficient system must be able to analyze enormous volumes of data, provide insightful analysis, or support the development of business computations.
Performance and Scalability
The crucial element is determining how well the system can scale up or down in response to the demands of the company and the quantity of concurrent users. A scalable AI Copilot may adjust to changing business needs without causing any disturbance, giving enterprises flexibility, cost-effectiveness, and consistent performance. Large data volumes are processed effectively as a result, resulting in quicker insights and decisions.
Combining with Current Systems
It is important to assess how well the product works with the organization's current stack, which consists of data warehouses, BI platforms, and visualization tools. Simplifying data access and analysis with a well-integrated AI Copilot boosts productivity and efficiency all around.
Personalization and Adaptability
Every company has different needs and procedures when it comes to data analytics. It is critical to have an AI Copilot system with flexibility and customization options to meet the unique needs of the company. Users are empowered to extract the most value possible from their data by a flexible system, which offers customisable dashboards and reports as well as personalized insights and suggestions.
Safety and Adherence
Verify that the AI Copilot conforms with applicable data protection laws and industry-standard security measures. Encryption, role-based access controls, and regulatory compliance are examples of strong security measures that assist reduce the risk of data breaches and associated fines.
Applications of AI Copilot
AI Copilots have the ability to simplify business procedures in a variety of sectors. They have the power to fundamentally alter how businesses use cutting-edge technology to streamline operations and extract useful information from massive volumes of data to improve decision-making. Copilots serve as a link between users and data, allowing users to speak with their data in normal language. This reduces the need for IT intervention and promotes an enterprise-wide data-driven culture.
Shop Analytics:
- Sophisticated trend analysis for sales information
- Development of a customized marketing plan
Analysis of Customer Behavior and Retention:
- Forecasting future actions
- Finding valuable clients
- Analytics for Supply Chains:
Enhancement of supply chain processes:
- Inventory management
- Analytics and Financial Planning:
- Projecting financial measurements
- Automation of financial reporting
Analytics for Manufacturing:
- Simplifying the production process
- Automation of maintenance scheduling
- Analytics for Healthcare:
Rapid evaluation of patient information
- Identifying patients that pose a significant risk
Conclusion:
Enterprise AI copilots are headed toward a more ethical, autonomous, and essential role supporting critical business operations. Robust natural language processing (NLP) skills, advanced analytical aptitude, and self-governing decision-making will combine to offer an intuitive interface for producing strategic recommendations and predictive insights. Businesses will be able to manage the complexity of dynamic business environments with the aid of this combination of intelligent and automated functions.
The development of ethical AI will be prioritized for reasons of openness, bias reduction, and regulatory compliance. In addition to ethical considerations, more stringent security measures will need to be put in place to protect data and guarantee adherence to changing regulatory requirements. These solutions are expected to accelerate research and development across multiple industries and play a critical role in promoting innovation in creative processes.
navan.ai has a no-code platform - nstudio.navan.ai where users can build computer vision models within minutes without any coding. Developers can sign up for free on nstudio.navan.ai
Want to add Vision AI machine vision to your business? Reach us on https://navan.ai/contact-us for a free consultation.