
We all know AI is an ocean and in that ocean, it's very hard to know each and every marine organism. Likewise, it's very hard to know AI terminologies, their differences, and most importantly what data can be used to build different models. Let us understand a bit more about Image Classification, Image Detection, and Image Segmentation.
Before we step in, let's discuss what exactly Computer Vision is. Computer vision is an area of artificial intelligence that deals with the task of extracting high-level understanding from digital images. Images are everywhere in the modern world and they contain a lot of valuable information. The ability to automatically detect and classify images is highly sought-after in many industries.
Computer vision is used in many different fields, including medical image analysis, driverless cars, and facial recognition. It is also used in manufacturing to detect defects in products, and in retail to track items and people.
There are many different approaches to computer vision, but one of the most popular approaches is image classification.
Image Classification
Image classification is a type of machine learning that involves training a model to recognize and classify objects in images. This is typically done by feeding the model a large dataset of labeled images, where each image has been annotated with the correct label or category. The model then uses this training data to learn how to identify and classify objects in new, unseen images. Once the model has been trained, it can be used to automatically classify objects in images, making it a powerful tool for a wide range of applications, such as object recognition, image search, and automated image tagging.
For example, an image classification algorithm might be tasked with classifying images as either “cat” or “non-cat”.
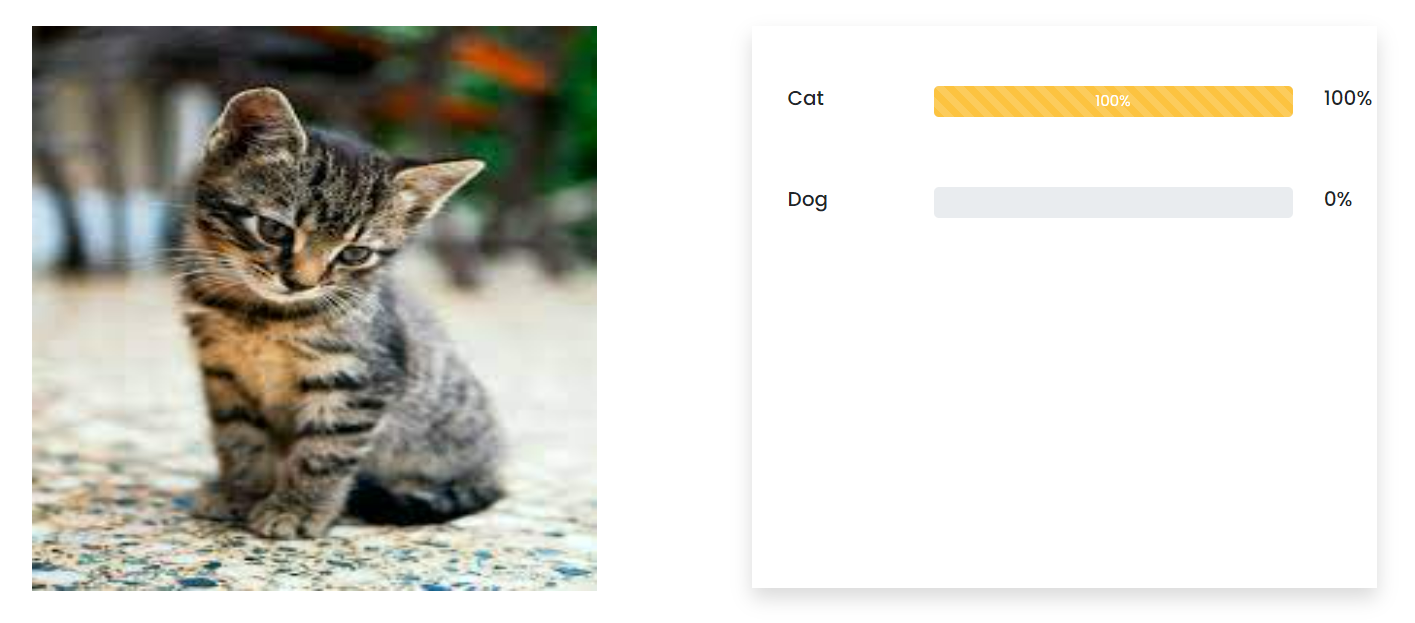
The process of image classification can be divided into three main steps:
- Pre-processing: This step involves performing various operations on the input image to prepare it for the classification process.
- Feature extraction: This step involves extracting features from the pre-processed image that will be used by the classifier.
- Classification: This step involves using the extracted features to classify the image into one or more classes.
Object Detection: Object detection is the process of identifying and classifying objects in an image. This can be done using a variety of methods, including traditional image processing techniques such as edge detection and template matching, or more modern methods such as deep learning. For example, We need to detect a table in the image or the chair in the image.

Deep learning is a particularly effective method for image detection, as it can learn to recognize objects in images without being explicitly told what to look for. This makes it well-suited for tasks such as detecting faces or objects in pictures
Image segmentation using computer vision Image segmentation is the process of partitioning an image into multiple segments. Image segmentation aims to cluster pixels into salient regions that correspond to different objects or themes in the image. In this, we will explore how computer vision can be used for image segmentation. Image segmentation is the process of dividing an image into multiple parts. In computer vision, image segmentation is used to identify objects, boundaries, and other features in images.
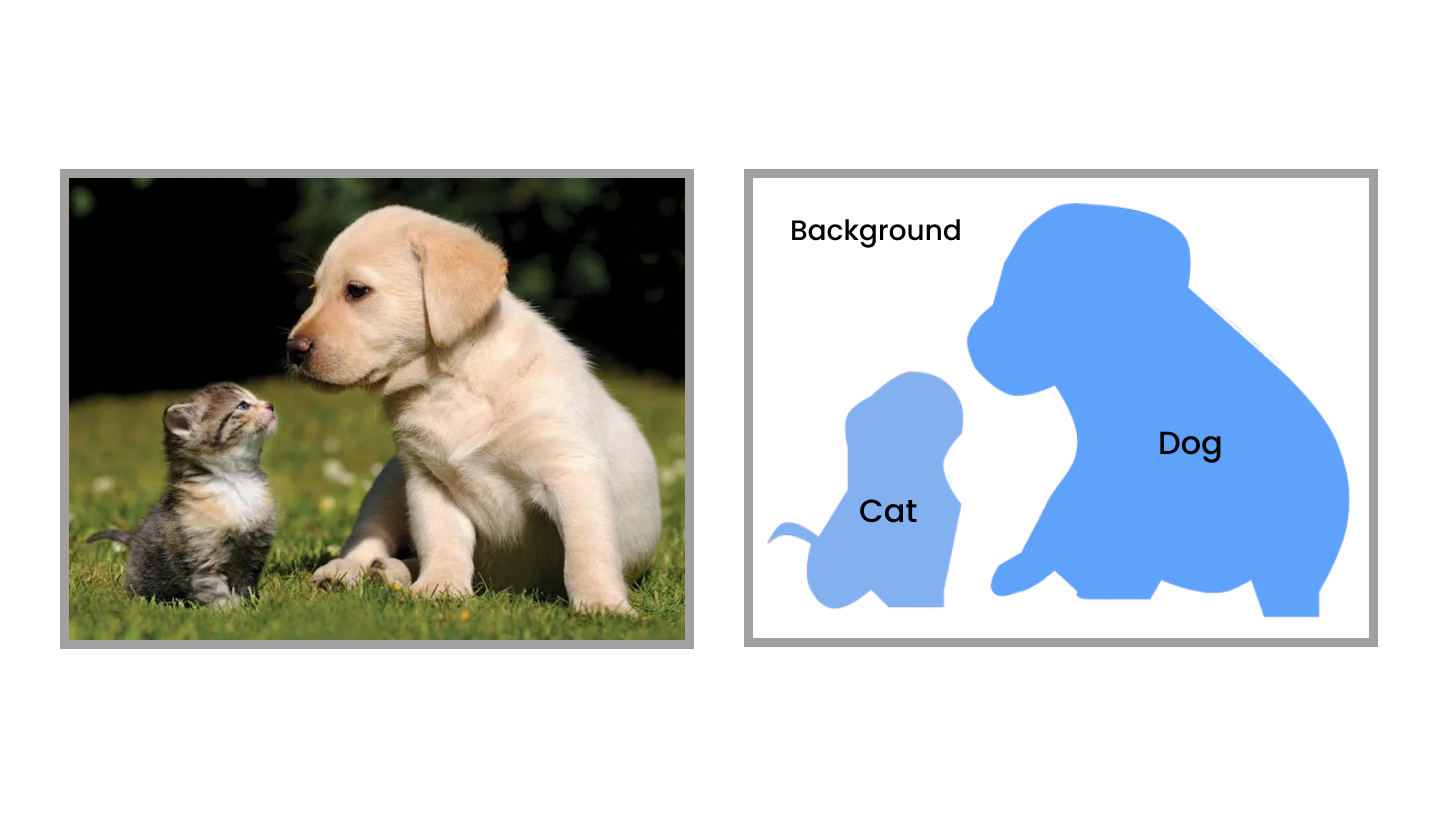
There are many different methods for image segmentation, but the most common approach is to use a thresholding technique. Thresholding is a process of converting an image into a binary form, where the pixels are either black or white.
To do this, we first need to determine the threshold value, which is the point at which a pixel is considered black or white. This can be done using histograms or other methods. Once the threshold value is determined, we can apply it to the image and convert it into a binary form.
The advantages of using thresholding for image segmentation are that it is simple to implement and can be easily automated. Additionally, thresholding can be applied to many images, including those with low contrast or noise.
However, there are also some disadvantages to using thresholding for image segmentation. One drawback is that it can produce over-segmented images, where too many small regions are identified. Additionally, thresholds can be sensitive to lighting conditions and background colors. Image segmentation can be used for object detection and recognition, medical image analysis, and other applications.
There are numerous applications of computer vision, some of which have already been discussed in this article. To know more and to participate in conversations with the machine vision developer community, follow navan.ai on LinkedIn and Twitter and tag us in your post which talks about the applications of computer vision developed by you.
Want to develop your own computer vision AI models without writing a single line of code? Visit navan.ai - a no-code platform for computer vision now and get started for free!