
Introduction:
For many years, people have been waiting for self-driving automobiles. Recent technological advancements have made this idea "possible".
One of the key technologies that made self-driving possible is deep learning. It's an incredibly flexible tool that can tackle nearly any problem; examples of its applications include the classification of images in Google Lens and proton-proton collisions at the Large Hadron Collider in physics.
A technology called deep learning can assist in resolving practically any kind of scientific or engineering issue.Convolutional neural networks (CNN), one of the deep learning algorithms used in self-driving automobiles, will be the main topic of this article.
How do self-driving cars work?
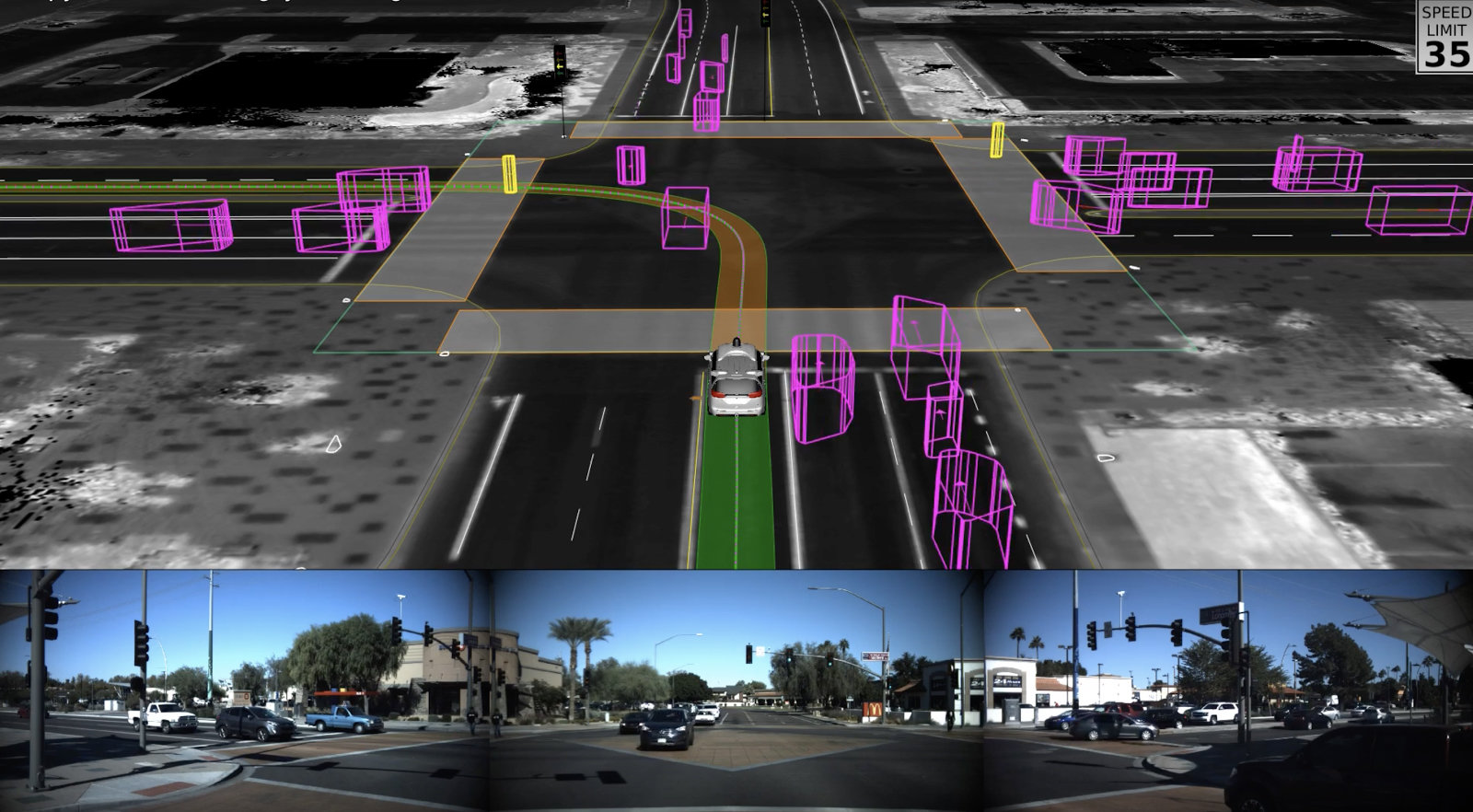
The Automatic Land Vehicle in Neural Network (ALVINN) was the initial self-driving car created in 1989. Neural networks were utilised for line detection, environment segmentation, self-navigation, and driving. It had limitations due to inadequate data and slow processing speeds, but it nevertheless functioned well.
Today's high-performance computers, graphics cards, and massive data sets make self-driving technology more potent than ever. It will improve road safety and lessen traffic congestion if it gains traction.
Self-driving automobiles are vehicles that can make decisions on their own. Data streams from many sensors, including cameras, LiDAR, RADAR, GPS, and inertia sensors, can be processed by them. Deep learning algorithms are then used to model this data and make decisions based on the context in which the car is operating.
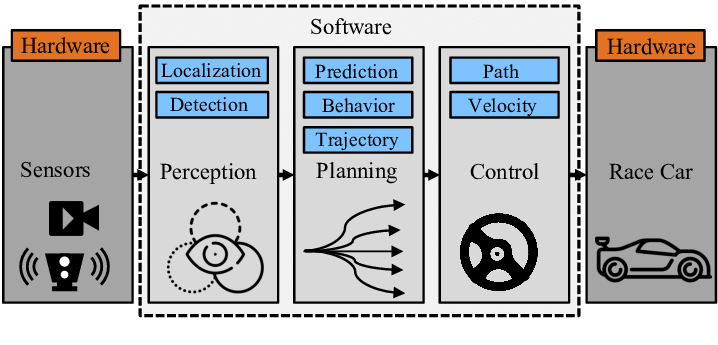
A modular perception-planning-action pipeline for making driving decisions is depicted in the above figure. The various sensors that gather data from the surroundings are the main elements of this technique.
We must look at the following four key components in order to comprehend how self-driving automobiles function:
Perception
Localization
Prediction
Decision Making
- High-level path planning
- Behaviour Arbitration
- Motion Controllers
1. Perception
Perception is one of the most crucial characteristics that self-driving cars need to possess since it allows the vehicle to view its surroundings and identify and categorise the objects it observes. The automobile needs to be able to identify items quickly in order to make wise selections.
Thus, the vehicle must be able to recognize and categorise a wide range of objects, including humans, road signs, parking spaces, lanes, and walkways. Furthermore, it must be aware of the precise separation between itself and the surrounding things. Beyond seeing and categorising, perception allows the system to assess distance and determine whether to brake or slow down.
Three sensors are required for a self-driving car to have such a high level of perception:
- Camera
- LiDAR
- RADAR
Camera:

The car's camera gives it vision, allowing it to perform a variety of functions like segmentation, classification, and localization. The resolution and accuracy of the cameras' representation of the surroundings must be good.
The cameras are stitched together to create a 360-degree image of the surrounding area, ensuring that the car receives visual input from all four directions. These cameras offer both a short-range view for more concentrated perception and a wide-range vision that extends up to 200 metres
The camera also offers a panoramic picture for enhanced decision-making in some jobs, such as parking.
Even while the cameras perform all perception-related functions, they are essentially useless in harsh weather situations like dense fog, torrential rain, and especially at night. All the cameras record in harsh weather circumstances are sounds and anomalies, which can be fatal.
We need sensors that can estimate distance and function in the absence of light in order to get around these restrictions.
LiDAR:
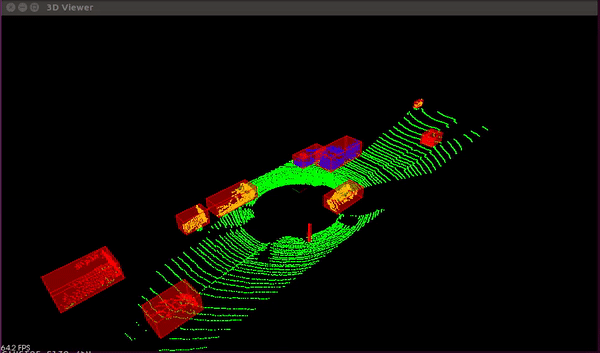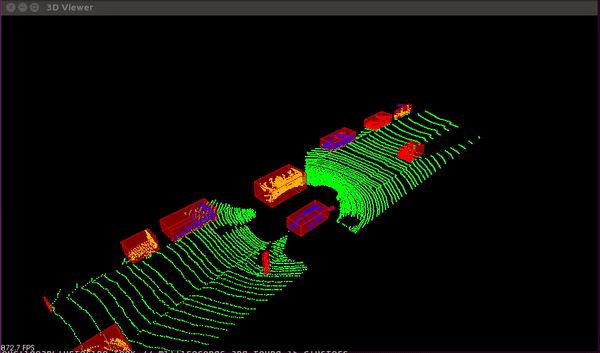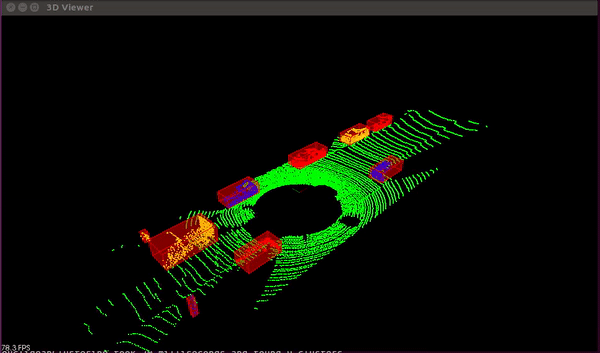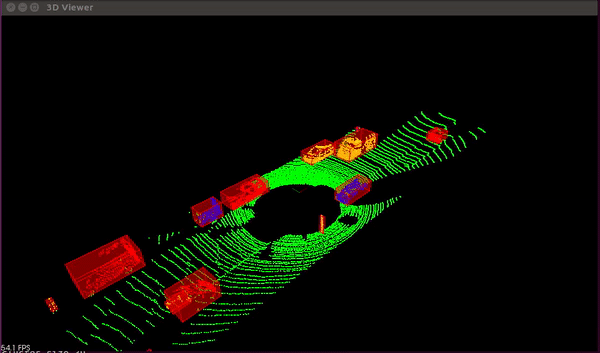
Light Detection and Ranging, or LiDAR for short, is a technique that uses a laser beam to determine an item's distance by timing how long it takes for the beam to be reflected off of an object.
The automobile can only get photographs of its surroundings from a camera. It acquires depth in the photos when paired with the LiDAR sensor, giving it an instantaneous 3D sense of the environment around the vehicle.
RADAR:

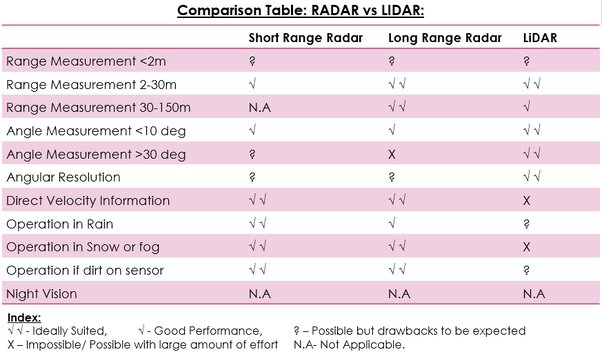
In many military and commercial applications, radio detection and ranging, or RADAR, is an essential component. The military was the first to use it for object detection. It uses radio wave waves to calculate distance. It is now a standard feature of many cars and is essential to self-driving cars.
Since RADARs operate in all environments due to their use of radio waves rather than lasers, they are very effective.To produce accurate judgments and forecasts, the RADAR data needs to be cleansed. Thresholding is the process of separating weak signals from strong ones. Fast Fourier Transforms (FFT) are another tool we employ to filter and analyse the data.
2. Localization
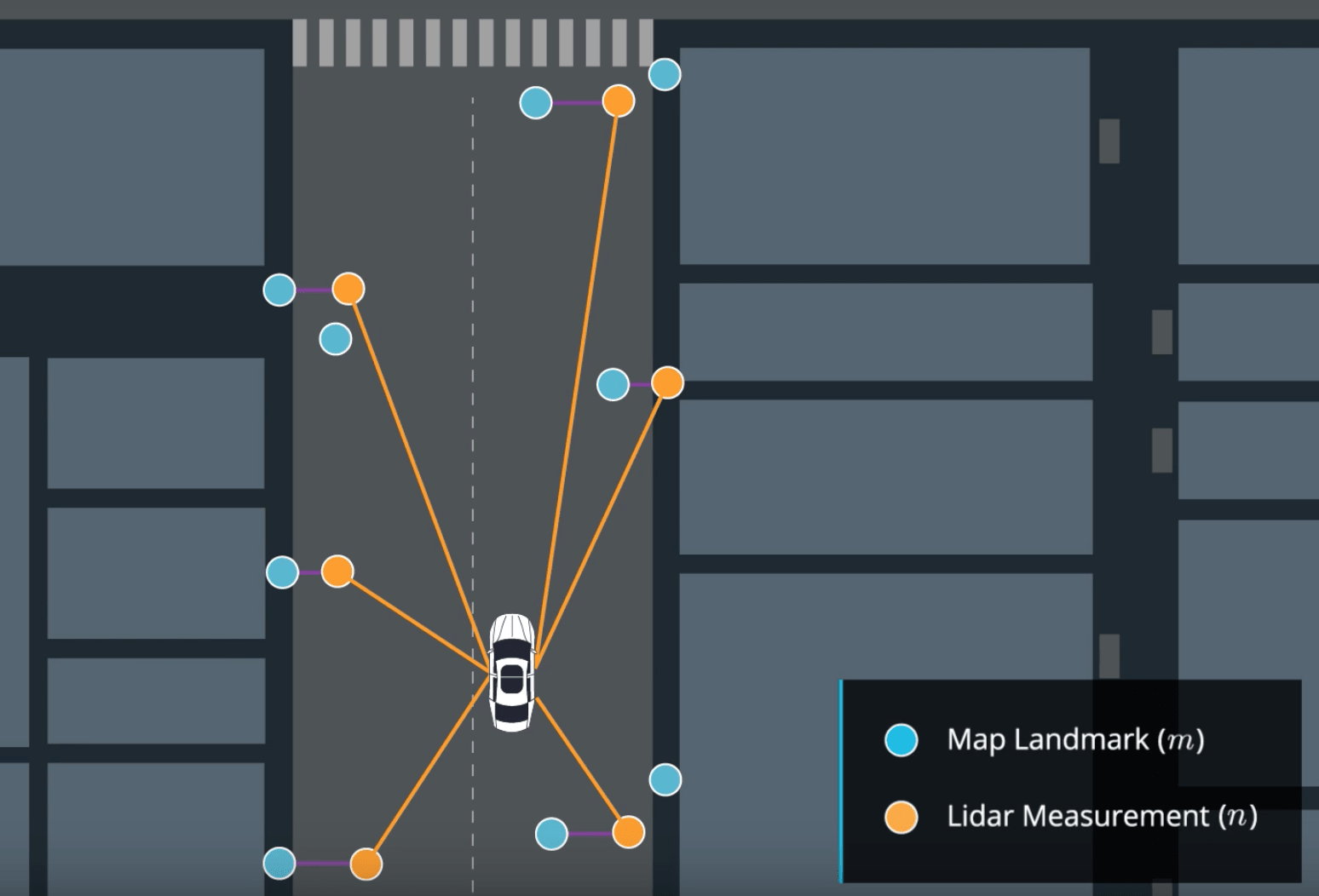
Self-driving car localization algorithms use a technique called visual odometry (VO) to determine the position and orientation of the vehicle while it navigates.
Vocabulary entails matching significant spots in a series of consecutive video frames. The salient features of each frame are fed into a mapping algorithm. Roads, pedestrians, and other adjacent items can be classified with the aid of mapping algorithms like Simultaneous Localization and Mapping (SLAM), which calculates the position and orientation of each object in relation to the previous frame.
Deep learning is typically used to identify various objects and enhance voice over network (VO) performance. A few frameworks that employ point data to estimate the 3D location and orientation are neural networks, such PoseNet and VLocNet++. As demonstrated in the graphic below, scene semantics can be derived from these approximated 3D coordinates and orientations.
3. Prediction
Self-driving cars are capable of segmentation, localization, object detection, image classification, and other tasks thanks to their sensors. The automobile can forecast the item around it using many types of data representation.
Images and cloud data points from LiDARs and RADARs can be modelled by a deep learning system during training. The vehicle can be made ready for any scenario that may entail stopping, braking, slowing down, changing lanes, and other manoeuvres by using the same model during inference.
Deep learning is used in self-driving automobiles to perform kinematic manoeuvres, improve perception, localise itself in the environment, and understand complicated vision tasks. This guarantees both a simple commute and road safety.
4. Decision making
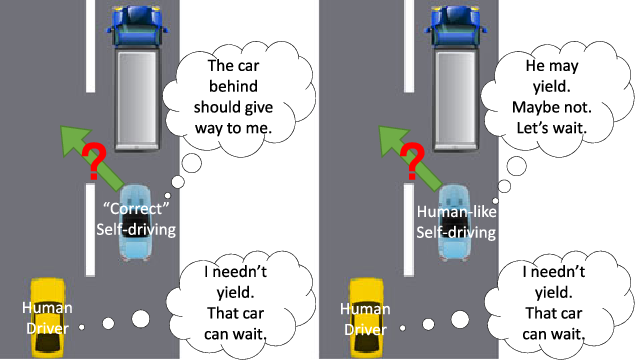
Making decisions is essential for self-driving automobiles. They require a precise and dynamic system in an unpredictable setting. It must consider the fact that human decision-making might be unexpected and that not all sensor data will be accurate when driving. These things are not directly measurable. We are unable to accurately forecast them, even if we could quantify them.
Convolutional neural networks, or CNNs,: what are they?
One kind of deep learning method that is frequently utilised in computer vision applications is the convolutional neural network (CNN). Capturing the spatial correlations between pixels in an image is the fundamental notion behind CNNs. A number of procedures, including convolution, pooling, and activation functions, are used to achieve this. The network then makes advantage of these connections to categorise the picture into distinct groups, such objects in a picture.
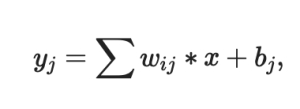
Where:
the operator * represents the convolution operation,
- w is the filter matrix and b is the bias,
- x is the input,
- y is the output.
In practical application, the filter matrix dimensions are typically 3 by 3 or 5 by 5. The filter matrix will continuously update itself to obtain an appropriate weight throughout the training phase. CNN's shared weights are one of its characteristics. Two distinct network transformations can be represented by the same weight parameters. By using a common parameter, the network may learn more varied feature representations while conserving a significant amount of processing space.
Most of the time, a nonlinear activation function receives the CNN output. The network can solve linear inseparable problems thanks to the activation function, and these functions can represent high-dimensional manifolds in lower-dimensional manifolds. The activation functions Sigmoid, Tanh, and ReLU are frequently utilised and are as follows:
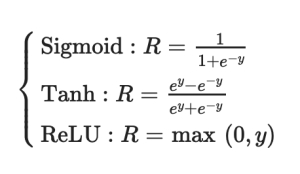
The ReLU is the recommended activation function since it converges more quickly than the other activation functions, which is important to note. Furthermore, the max-pooling layer modifies the convolution layer's output by retaining additional details from the input image, such as the texture and backdrop.
Three crucial characteristics of CNNs are what make them adaptable and a key element of self-driving cars:
- local receptive fields,
- shared weights,
- spatial sampling.
HydraNet – semantic segmentation for self-driving cars by Tesla:

In 2018, Ravi et al. introduced HydraNet. It was created to increase computational efficiency during the inference process for semantic segmentation.
Because of its dynamic architecture, HydraNets can have several CNN networks, each with a distinct task assigned to it. We refer to these networks or blocks as branches. Various inputs are fed into a task-specific CNN network using HydraNet's concept.
Consider the scenario of autonomous vehicles. An input dataset may consist of static surroundings such as roadside trees and railings, another of the road and lanes, still another of the road and traffic signals, and so forth. Several branches have trained these inputs. The gate selects which branches to execute during the inference period, and the combiner compiles branch outputs before rendering a judgement.
Due to the challenge of separating input for each task during inference, Tesla has made minor modifications to this network. The engineers at Tesla created a shared backbone as a solution to that issue. Modified ResNet-50 blocks are typically used as the common backbones.
The whole object's data set is used to train this HydraNet. The model can forecast task-specific outcomes since it has task-specific heads. The heads are built using an architecture for semantic segmentation similar to the U-Net.
In order to provide the Tesla HydraNet with considerably more dimensionality for accurate navigation, it can also project a birds-eye view, or a three-dimensional representation of the surroundings from any angle. It's critical to understand that LiDAR sensors are not used by Tesla. It just has two sensors: a radar and a camera. Tesla's hydranet is so effective that it can stitch together all the visual data from the 8 cameras in the car to produce depth perception, even though LiDAR expressly creates it for the vehicle.
Conclusion:
Convolutional neural networks, or CNNs, are essential to the development of self-driving automobiles, to sum up. CNNs contribute to improved driving accuracy and safety by utilising image recognition to comprehend the surrounding environment. The application of CNNs in self-driving cars is probably going to keep developing and getting better as long as technology keeps going forward, which will make these vehicles even more practical in the long run.
navan.ai has a no-code platform - nstudio.navan.ai where users can build computer vision models within minutes without any coding. Developers can sign up for free on nstudio.navan.ai
Want to add Vision AI machine vision to your business? Reach us on https://navan.ai/contact-us for a free consultation.