
Gesture classification using computer vision involves recognizing and categorizing hand or body movements captured by cameras as input, with the goal of inferring the intended gesture. This can be achieved through various techniques such as image processing, machine learning, and deep learning.
The process starts with capturing video or image data of the gestures, followed by preprocessing and feature extraction. After that, the features are fed into a machine-learning model that has been trained to recognize gestures, resulting in the classification of the input gesture. This technology has various applications in human-computer interaction, gaming, sign language recognition, and other fields.

Gesture classification in AI is used for a number of reasons:
1. Human-Computer Interaction: It allows for more intuitive and natural interaction between humans and computers, making it possible to control devices using gestures instead of traditional input methods such as a mouse or keyboard.
2. Gaming: In gaming, gesture classification can be used to control game characters, allowing players to interact with the game environment in a more immersive way.
3. Motion capture: Motion capture systems use gesture classification to track human movements for animation and special effects in films and video games.
4. Sign Language Recognition: It can be used to recognize and translate sign language into speech, making communication easier for the hearing impaired.
5. Healthcare: In healthcare, gesture classification can be used to monitor and track physical therapy progress, helping medical professionals to evaluate and improve patients' rehabilitation progress.
These are some of the reasons why gesture classification in AI is used, and it has the potential to revolutionize the way we interact with technology and each other.

Case study:
One example of a gesture classification AI model that has been implemented is the Xbox Kinect gesture recognition system. The Xbox Kinect was a gaming peripheral released by Microsoft in 2010 that used a combination of cameras, microphones, and infrared sensors to recognize and track players' body movements.
The system used a combination of computer vision and machine learning techniques to classify player gestures and movements, allowing players to control the game without a traditional game controller.
The different steps involved in the process:
- Data Collection: The Xbox Kinect system collected data on player movements using its cameras and sensors.
- Preprocessing: The data was preprocessed to extract relevant information, such as the position and orientation of the player's limbs.
- Feature Extraction: The extracted information was used to extract features that could be used to train the model, such as the player's limb angles and movements.
- Model Training: A machine learning model was trained using the extracted features to recognize and classify player gestures.
- Testing and Validation: The trained model was tested and validated on a separate dataset to evaluate its accuracy.
- Deployment: The trained model was then deployed in the Xbox Kinect system, allowing players to control the game using their body movements.
This case study shows how gesture classification using AI was successfully implemented in a real-world application, allowing for a more natural and intuitive form of interaction between players and the game.

How navan.ai can help you build a gesture recognition/classification model without having to write a single line of code?
1. Visit nstudio.navan.ai, and sign up using your Gmail id.
2. Choose a suitable model architecture: EfficientNet-B2 is a pre-trained deep learning model designed for computer vision tasks such as image classification, object detection, and segmentation. It is based on the Convolutional Neural Network (CNN) architecture and is designed to improve upon the previous EfficientNet models in terms of both accuracy and computational efficiency. The "B2" in the name refers to the model's size, which is determined by a combination of the depth, width, and resolution of the network.
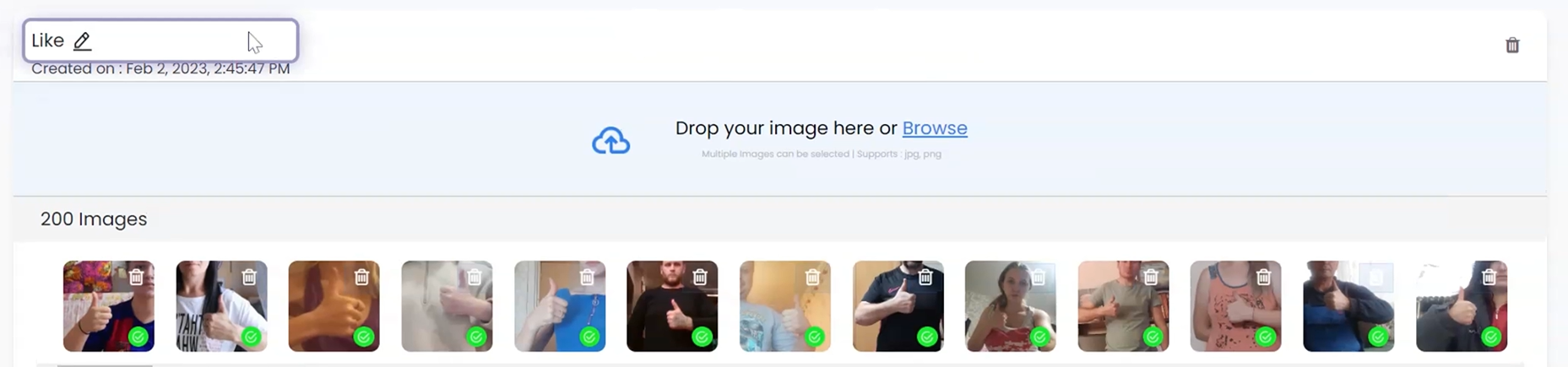
3. Training the model: We are considering 5 classes here, One [like] , Two [dislike], Three [fist], Four[rock], and Five[mute] and we have named the Model “GESTURE CLASSIFICATION”. We create a class for each category. After we upload images into each class, the model is ready to be trained.
The images are uploaded to Class 1 - Like
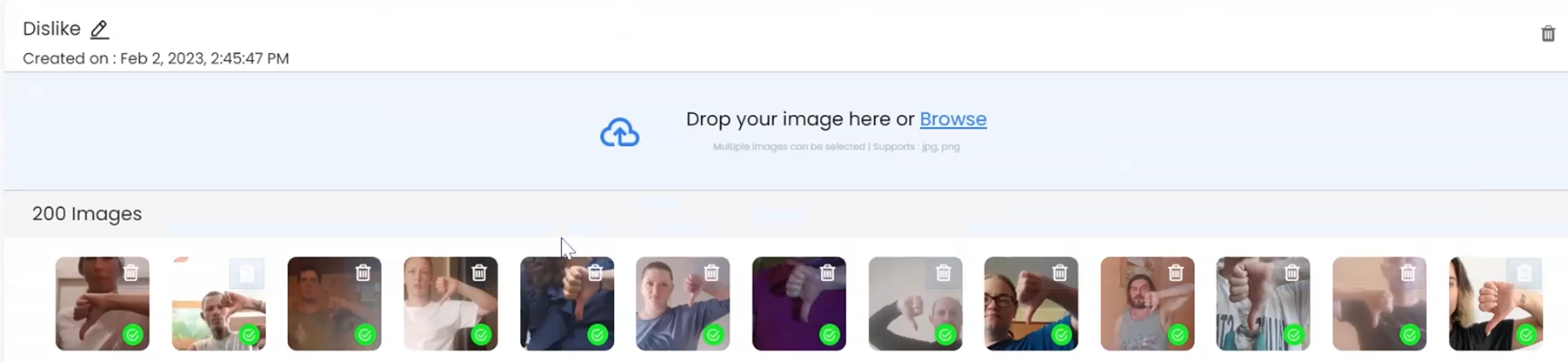
The images are uploaded to Class 2 -Dislike
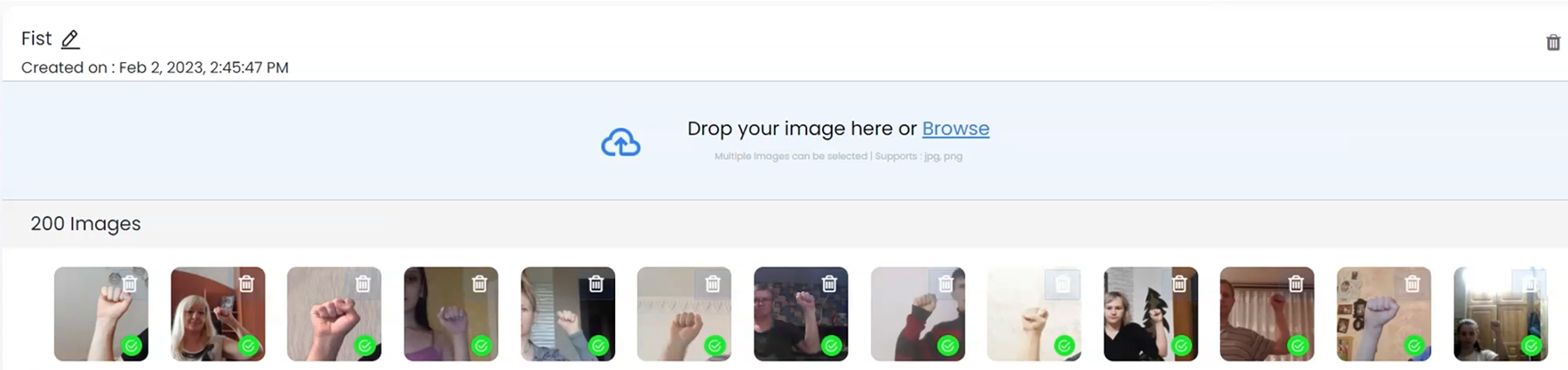
The images are uploaded to Class 3 -Fist
The images are uploaded to Class 4 -Rock
The images are uploaded to Class 5 -Mute
The next step is to click on the start training button so that the model can be trained.
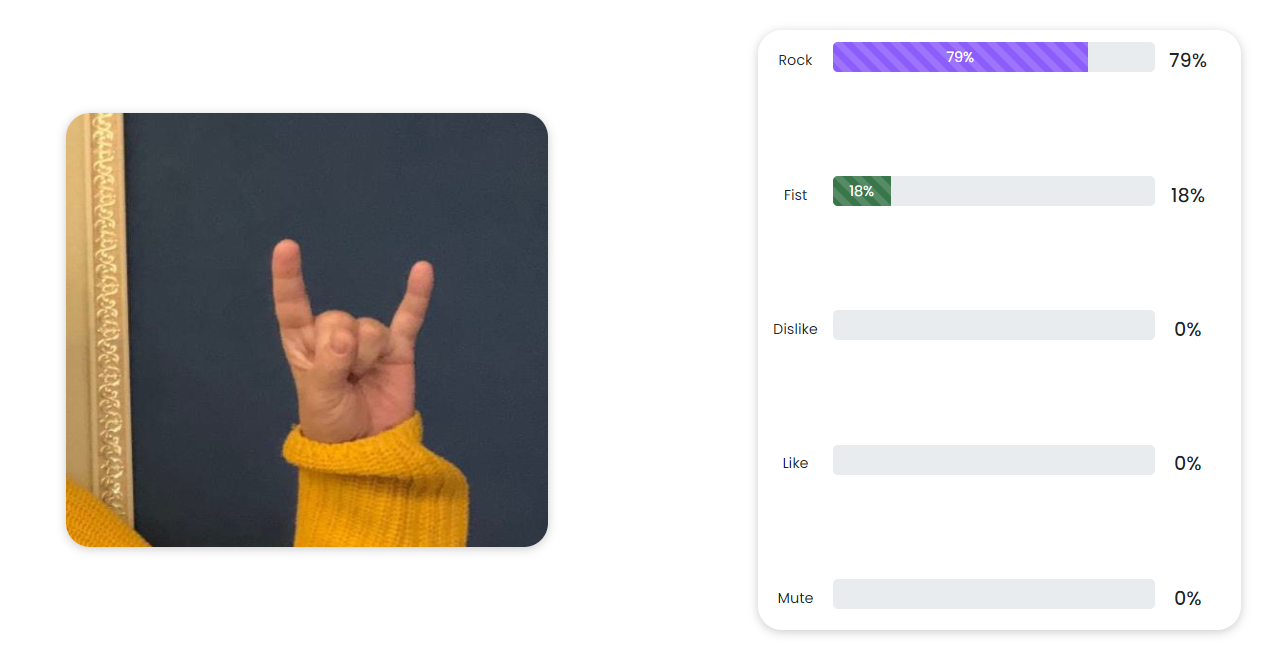
4. Testing the model: Once the GESTURE CLASSIFICATION model has been trained, the next step is to test the model to see if it is performing according to our expectations. It can be evaluated using a separate test dataset to determine its performance and make any necessary adjustments before deploying it in a real-world application.
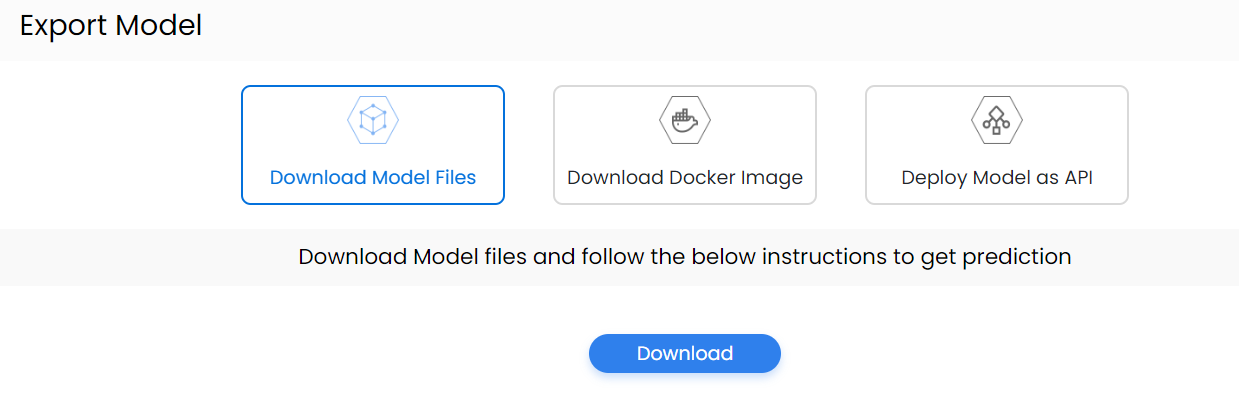
5. Deploying the model: The easiest way to deploy the computer vision model is by using the list of export models on navan.ai. We have 3 options: Deploy a model using Model files, Deploy a model through Docker, and lastly deploy the model as API. You can integrate the model with your application to get a scalable use case and build using your data without any coding on navan.ai.
6. The model once trained, the classes can be seen like this

Here’s a video showing how you can build a Gesture Recognition Computer Vision AI Model on navan.ai:

navan.ai is a no-code computer vision platform that helps developers to build and deploy their computer vision models in minutes. Why invest 2 weeks in building a model from scratch when you can use navan.ai and save 85% of your time and cost in building and deploying a computer vision model? Build your models, share knowledge with the community, and help us make computer vision accessible to all. navan.ai also helps organizations with MLOps by setting up CT, CI, and CD pipelines for ML applications.
Visit navan.ai and get started with your computer vision model development NOW!