
Introduction:
The newest model, YOLOv8, is a member of the most well-known family of object recognition and classification models in the field of computer vision (CV), the YOLO algorithm series.Thanks to the incorporation of many modifications including spatial attention, feature fusion, and context aggregation modules, it performs better than previous iterations.These improvements result in faster and more accurate object detection, making YOLOv8 one of the most significant object detection algorithms in the market.
This article introduces the most recent version of Ultralytics' YOLOv8, a well-known real-time object recognition and image segmentation model. This version offers remarkable speed and accuracy by utilising the most recent advancements in computer vision and deep learning. Because it's implemented in the user-friendly Ultralytics Python package, its effective architecture supports a broad range of applications and can be easily adapted to a variety of hardware platforms, from edge devices to cloud APIs.precise identification of objects.
What is Object detection in computer vision?

In computer vision, object detection is the process of recognizing and localising objects inside an image or video frame. This basic computer vision problem has several applications, such as in robots, autonomous cars, surveillance, augmented reality, and medical imaging. The objective is to draw bounding boxes around items to precisely identify their locations in addition to identifying what objects are there in an image.
Typical process involved in object detection:
1. Input: A picture or a video frame is used to start the process.
2. Feature Extraction: To begin, the system takes the input image and extracts pertinent features. Convolutional neural networks (CNNs) and other similar approaches may be used in this procedure to record hierarchical representations of the image.
3. Object Localization: Detecting objects in an image entails both identifying their presence and pinpointing their location. Predicting bounding boxes that closely encompass the objects of interest is a common method used to do this. Bounding box coordinates and confidence scores for each object spotted are output by a number of object detection models.
4. Object Classification: Following the object's localization, each detected object is categorised into one of the system's predetermined classifications. This is an important stage in figuring out what things are in the picture.
5. Post-processing: To further improve the outcomes after object localization and classification, post-processing techniques like non-maximum suppression (NMS) may be used. NMS assists in removing overlapping or superfluous bounding boxes, keeping just the most reliable detections.
6. Output: The bounding boxes surrounding detected objects, together with the confidence ratings and accompanying class labels, are usually included in the final output.
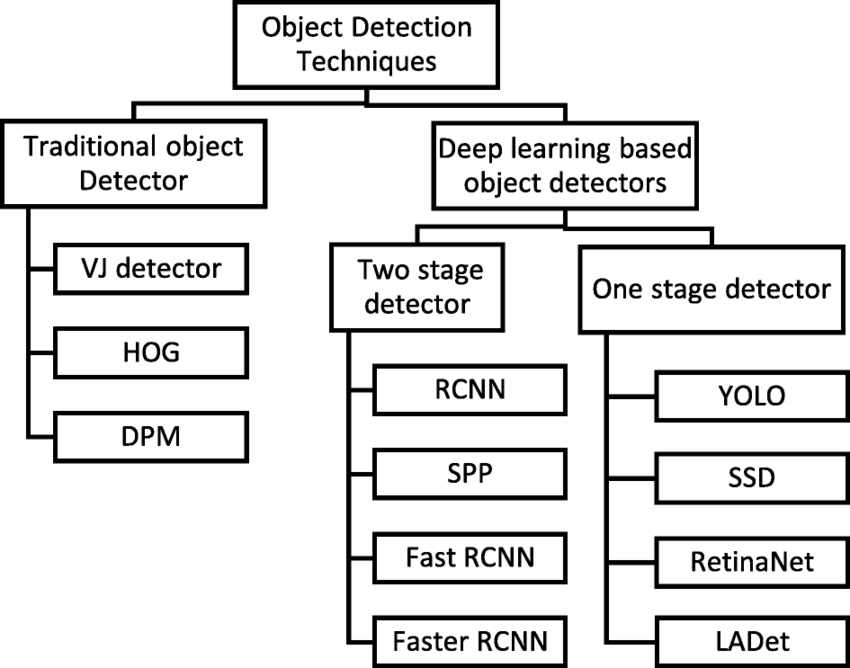
1. Conventional Techniques:
*Feature-based Methods: These techniques use conventional machine learning algorithms (such as Histogram of Oriented Gradients and Haar cascades) in conjunction with manually created features to detect objects.
*Template matching: It is the process of looking for instances of a template by comparing a template image with the target image.
*Edge detection: recognizes items by looking for edges in pictures.
2. Deep Learning-Oriented Techniques:
*Two-Stage Detectors: These techniques first identify potential regions of interest (RoIs) before categorising them. R-CNN, Faster R-CNN, and its variations are a few examples.
*One-Stage Detectors: Immediately forecast class probabilities and bounding boxes from the full image in a single step. YOLO (You Only Look Once), SSD (Single Shot Multibox Detector), and RetinaNet are a few examples. Detectors with and without anchors: While anchor-free approaches anticipate item bounding boxes directly without the need for anchors, anchor-based methods need predetermined anchor boxes to do so.
3. Scale of Detection:
Identifies a solitary object within a picture using single object detection.
*Multi-Object Detection: Finds several objects in a picture that belong to distinct classes.
*Small Object Detection: This type of object detection is used to identify small objects in images from satellites or medical equipment. huge-Scale Object Detection: This technique looks for huge things in satellite images or aerial photos, such as cars or buildings.
4. Domain-Dependent Object Recognition:
Pedestrian detection is the process of looking for pedestrians in pictures or videos. It is frequently used by autonomous cars and surveillance systems. Face detection: Especially made to identify faces in people, this technology is frequently employed in surveillance, photo tagging, and facial recognition applications. Vehicle detection is the process of looking for cars in parking lots, traffic scenes, or aerial photography. It is frequently employed in surveillance and transportation management. Medical object detection is the process of looking for anomalies or particular organs in medical pictures like CT, MRI, or X-rays. Instantaneous Object Recognition:
5. Real-Time Object Detection:
These techniques can identify things in real-time applications like robotics, autonomous driving, and video surveillance since they are designed for quick inference.
Introduction to YOLO:

"You Only Look Once," or YOLO, is a well-liked deep learning-based object identification system that is renowned for its effectiveness and quickness. In a study published in 2016, Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi presented it under the title "You Only Look Once: Unified, Real-Time Object Detection."
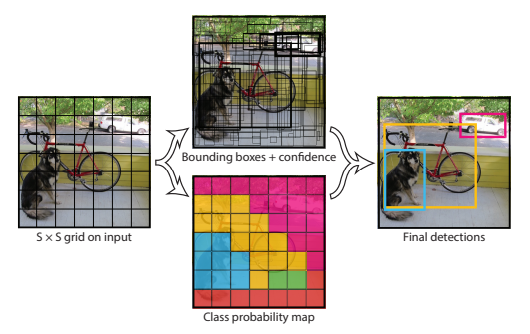
How does YOLO work?
In order for YOLO (You Only Look Once) to function, the input image is divided into a grid of cells, and bounding boxes and class probabilities are simultaneously predicted for each cell. Here's a more thorough explanation of how YOLO functions:
1. Input image: A fixed-size input image is used to start the procedure. To maintain uniformity between photos, YOLO resizes the input image to a preset size. YOLO uses a convolutional neural network (CNN) as the foundation for its feature extraction process. With the help of this network, high-level representations of objects, textures, and forms are extracted from the input image.
2. Grid Division: YOLO creates a ⁰× ⁰ N×N grid of cells from the supplied image. For items that fall inside each cell, the task of forecasting bounding boxes and class probabilities falls on them.
3. Bounding Box Prediction: YOLO projects a set number of bounding boxes—often indicated by the letter B—for every grid cell. Typically, these bounding boxes have coordinates (x, y) for the height, width, and center of the box. Furthermore, YOLO predicts confidence scores, which express the degree of the model's certainty that the bounding box contains an object and the precision of the box's coordinates.
4. Class Prediction: YOLO forecasts the class probabilities for every bounding box in addition to the bounding box coordinates and confidence scores. For every box, the model allocates a probability distribution across the predefined set of object types. As a result, things can be recognized by YOLO and categorised into various groups. YOLO employs anchor boxes to make the bounding box prediction process easier. Anchor boxes are prefabricated forms with various scales and aspect ratios. To better suit the objects in the dataset, YOLO modifies these anchor boxes during training depending on the ground truth bounding boxes.
5. Output Processing: YOLO filters out low-confidence detections by applying a threshold to the confidence scores after the prediction. Next, it uses non-maximum suppression (NMS) to retain only the most reliable bounding boxes for each class, so removing duplicate detections.
6. Final Output: The bounding boxes that represent the items that were detected, together with the class labels and confidence ratings that correspond to them, make up the final output of YOLO.
What’s new in yoloV8?
An improved network architecture intended to increase effectiveness and performance Updated design for anchor boxes: In order to improve the identification of item scales and aspect ratios within particular classes, anchor boxes have undergone restructuring. More accurate object localization and recognition in object detection models is ensured by these predefined bounding boxes, which are designed to match the sizes and variances of objects in training datasets. modified loss function to raise forecast accuracy overall YOLOv8 incorporates a self-attention mechanism located in the network's head coupled with an altered CSPDarknet53 backbone.
yoloV8 architecture overview:
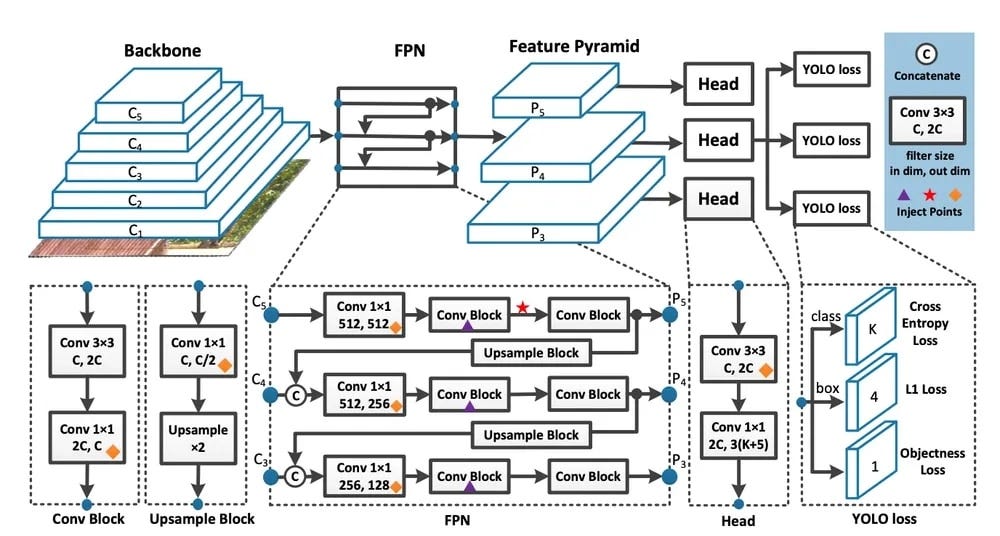
Training and Using YOLOv8 Model for Object Detection:
1. Fine-Tuning: The fine-tuning feature of YOLOv8 permits customization and specialization in object detection. In order to increase the model's performance and accuracy for identifying specific classes of objects, fine-tuning entails training the model on a particular dataset.
2. Dataset: You require a dataset with pictures and the associated annotations or labels in order to train YOLOv8. A variety of examples of the objects you want the model to identify should be included in the dataset. To train the YOLOv8 model, you can use the path to the dataset descriptor file, which defines the location and format of the dataset, and the "train" method.
3. Image Prediction: You can utilise the YOLOv8 model for picture prediction after you've trained it. The model may be used to evaluate a picture and produce predictions about the existence and placement of items by invoking the "predict" method and passing it an image. Essential data like bounding boxes, which define the object regions, and class labels, which identify the identified item types, are included in the prediction's output.
4. Bounding boxes: Because they indicate the positions of things that have been recognized within images, bounding boxes are essential to object detection. With the help of YOLOv8, you can precisely determine the location and extent of each detected object by using its accurate bounding box predictions.
5. Classes: Classes in object detection relate to the many groups or kinds of items that you wish the YOLOv8 model to identify. YOLOv8 allows the identification and classification of a variety of object classes, regardless of whether you are using predefined classes in a pre-trained model or modifying the model to detect specific classes from your dataset.
Steps for Training YOLOv8:
First, make sure the dataset is ready by making sure it has labels and photos. Provide the file path for the dataset description. To train the YOLOv8 model, use the dataset descriptor file and the "train" method. By training the model on particular object classes of interest, you can fine-tune it.
Steps for Image Prediction:
Load the YOLOv8 model after training. Make use of the "predict" method and supply an analysis input image. Obtain the forecasts along with the class labels and bounding boxes.
Key Features of YOLOv8:
Because of its many strong characteristics, YOLOv8 is a great option for object detection tasks. To meet your needs, YOLOv8 has a range of possibilities, whether you need to use pre-trained models or build custom models for particular item kinds. Let's get more into these salient characteristics:
1. Pre-trained Models: You can use pre-trained models with YOLOv8 that have already been trained on a large dataset like COCO (Common Objects in Context). These models are appropriate for a variety of object identification applications since they can recognize and categorise a large variety of things.
2. Custom Models: YOLOv8 gives users the ability to build custom models that are suited to their unique object detection requirements, in addition to pre-trained models. In order to do this, you must first prepare your training dataset by choosing and labeling the relevant object categories. You can attain greater accuracy and precision for object detection tasks that are specific to your application domain by training a custom model.
3. Preparing Data: An essential first step in using YOLOv8 to train bespoke models is data preparation. To give the model correct instances of the intended object kinds, it entails meticulously selecting and categorising the training dataset. Careful preparation of the data has a big impact on how well the object detection model works.
4. Support for Web Applications: By enabling the development of web applications for real-time object identification, YOLOv8 goes one step further. YOLOv8's integration with web browsers makes it possible for users to create reliable and user-friendly object detection interfaces without installing extra software.
Innovations and Enhancements to the YOLOv8 Architecture:
YOLOv8 solidifies its standing as a state-of-the-art deep learning model for object detection by introducing a number of improvements and changes to its architecture. These developments revolutionise the field of computer vision by optimising performance, accuracy, and efficiency.
1. A Better Architecture for Networks: YOLOv8's network design has been significantly enhanced. For performance optimization, modules and convolutions have been swapped out, making object detection quicker and more precise. With these improvements, YOLOv8 is able to process data in real time even for big datasets.
2. Unanchored Identification: Anchor-free detection, a novel method that automatically predicts bounding boxes at an object's centre, is incorporated into YOLOv8. Because preset anchor boxes are no longer required, the model is more durable and flexible enough to accommodate a wider range of item sizes and forms. Anchor-free detection guarantees accurate detection outcomes by improving object localization accuracy.
3. Techniques tricks to Improve Your Accuracy: YOLOv8 uses clever training techniques to increase object detection accuracy. One of the tips is to halt mosaic augmentation—a method that blends several images into a single training sample—prior to the training session's conclusion. This calculated change avoids overfitting and improves the model's overall performance, which leads to higher detection accuracy.
4. Decoupled Head Approach: The decoupled head technique, a major advancement in deep learning architecture, is used by YOLOv8. YOLOv8 is able to accomplish more accurate and efficient object detection by removing the objectness branch. The architecture of the model is made simpler by this streamlined design, which also increases inference speed and decreases computing complexity without sacrificing detection performance.
Conclusion:
YOLOv8 is a significant breakthrough in computer vision for real-time object recognition. With its improved architecture and state-of-the-art features, its deep learning model allows for extremely accurate object detection in a variety of applications.It is a premier deep learning model for object detection that improves on the achievements of its predecessors. Because of its cutting-edge algorithm and sophisticated computer vision methods, experts in the area always choose it.
navan.ai has a no-code platform - nstudio.navan.ai where users can build computer vision models within minutes without any coding. Developers can sign up for free on nstudio.navan.ai
Want to add Vision AI machine vision to your business? Reach us on https://navan.ai/contact-us for a free consultation.