
Introduction:
This is the age of the AI revolution. It promises amazing breakthroughs and is upending every industry it touches, but it also brings with it new difficulties. Semantic search, generative AI, and applications using massive language models have made efficient data processing more important than before.
Vector embeddings, a kind of vector data representation that contains semantic information essential for the AI to comprehend and retain a long-term memory they may call upon when performing complex tasks, are the foundation of all these new applications.
Embeddings are produced by AI models, like Large Language Models, and have a large number of characteristics, which makes managing their representation difficult. These features, in the context of AI and machine learning, stand for various data dimensions that are critical to comprehending relationships, patterns, and underlying structures.
A vector database: what is it?

A vector database is a type of database that specialises in storing and managing vector data. Vector data represents geometric objects such as points, lines, and polygons, often used to represent spatial information in geographic information systems (GIS) or in computer graphics applications.
In a vector database, each object is represented as a set of coordinates (x, y, z for 3D data) and associated attributes. These databases are designed to efficiently store and query vector data, allowing for operations such as spatial analysis, geometric calculations, and visualisation.
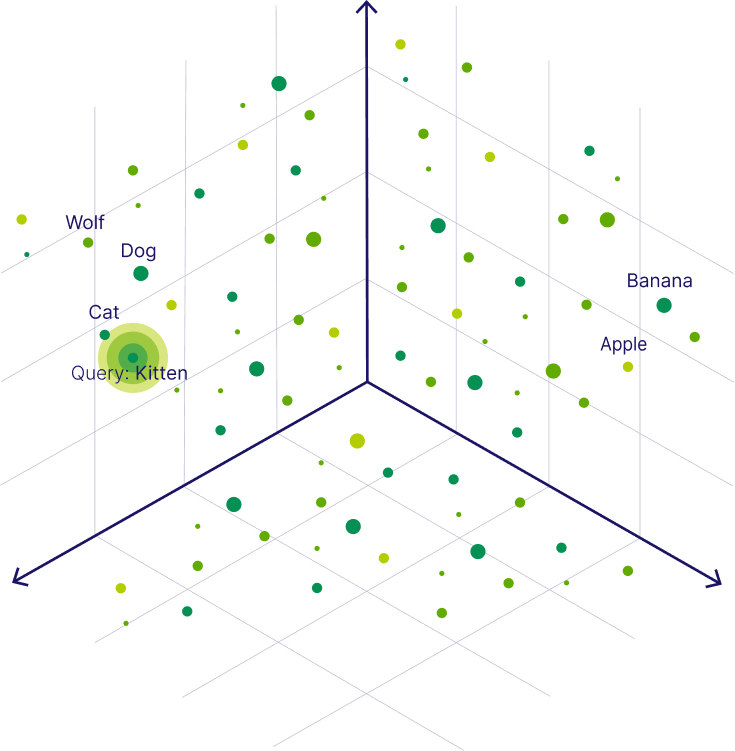
Vector databases are commonly used in various fields including geography, cartography, urban planning, environmental science, and computer-aided design (CAD). They provide a flexible and powerful way to manage and analyse spatial data, enabling users to perform complex spatial analyses and make informed decisions based on geographic information. Popular examples of vector databases include PostGIS, Oracle Spatial, and Microsoft SQL Server Spatial.
Vector embeddings: what are they?
A numerical representation of a subject, word, image, or any other type of data is called a vector embedding. Embeddings, or vector embeddings, are produced by AI models, including huge language models. What allows a vector database, or vector search engine, to calculate the similarity of vectors is the distance between each vector embedding. In order to help machine learning and artificial intelligence (AI) comprehend patterns, correlations, and underlying structures, distances can represent multiple dimensions of data items.
Why a vector database?
More complex designs are being introduced into the upcoming generation of vector databases in order to manage the effective cost and scaling of intelligence. Serverless vector databases, which may split the cost of computation and storage to provide low-cost knowledge support for AI, manage this capability.
We can give our AIs additional knowledge through the use of a vector database, including long-term memory and semantic information retrieval.
The following diagram helps us comprehend the function of vector databases in this kind of application:
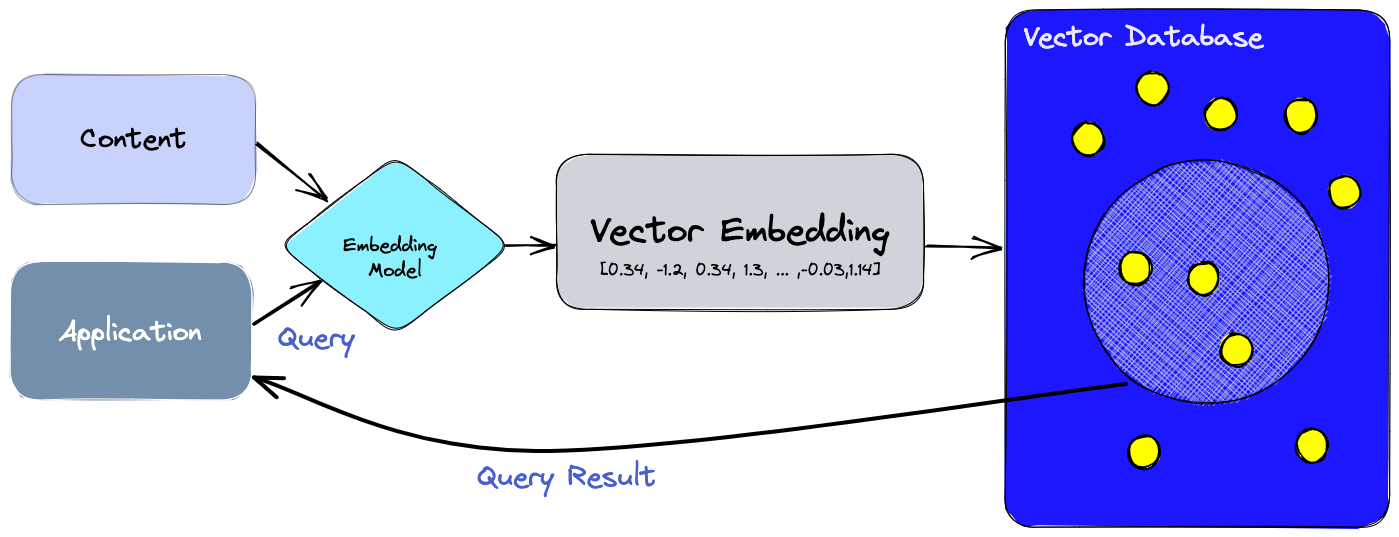
Let's dissect this:
Initially, we generate vector embeddings for the content we wish to index using the embedding model.
The vector embedding is added to the vector database along with a brief mention of the source material from which it was derived.
We build embeddings for queries issued by the application using the same embedding model, and then we query the database for vector embeddings that are similar to those embeddings using those embeddings. As previously stated, the original content that was used to construct those similar embeddings is linked to them.
How do vector databases work?
Traditional databases store strings, numbers, and other scalar data in rows and columns, as is generally understood to be the case. However, a vector database is optimised and searched differently because it relies on vectors for its operations.
When using a traditional database, we typically search for rows where the value precisely matches our query. To identify a vector in vector databases that most closely matches our query, we use a similarity metric.
An approximate nearest neighbour (ANN) search is carried out using a variety of techniques combined in a vector database. These algorithms use graph-based search, quantization, or hashing to maximise the search.
These techniques are combined to form a pipeline that retrieves a vector's neighbours quickly and accurately. The vector database yields approximations, thus the primary trade-offs we take into account are those between speed and accuracy. The query will execute more slowly the more accurate the result. Still, a well-designed system can offer lightning-fast search times with almost flawless precision.
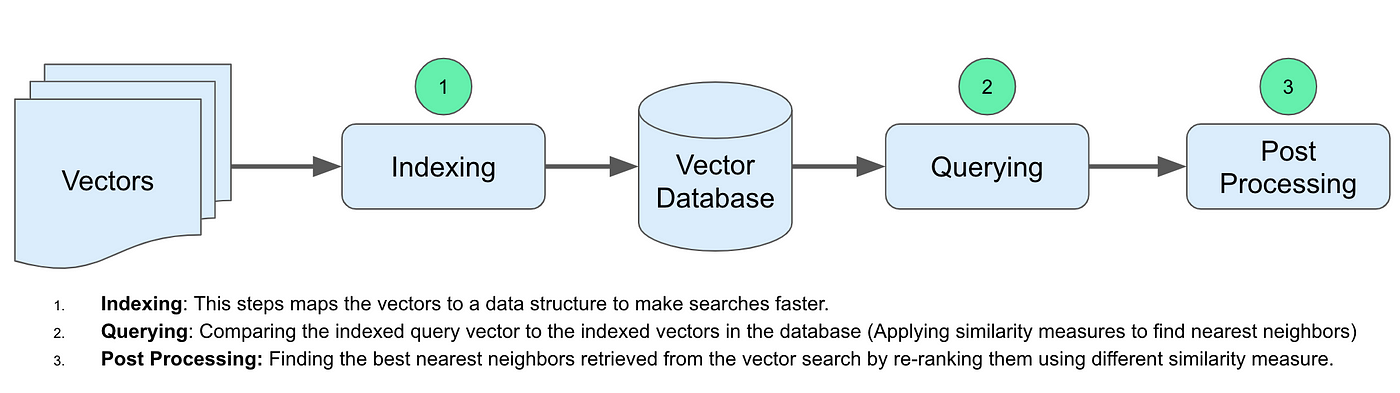
1. Indexing: An algorithm like PQ, LSH, or HNSW is used by the vector database to index vectors (more on these below). To enable speedier searching, this phase transfers the vectors to a data structure.
2. Querying: Using a similarity metric applied by that index, the vector database locates the closest neighbours by comparing the indexed query vector to the indexed vectors in the dataset.
3. Post-processing: To return the final findings, the vector database may occasionally extract the data set's last nearest neighbours and post-process them. Reordering the closest neighbours according to a new similarity metric may be part of this process.
What distinguishes a vector database from a vector index?
Although they lack features found in any database, standalone vector indices such as FAISS (Facebook AI Similarity Search) can greatly enhance the search and retrieval of vector embeddings. In contrast, vector databases are designed specifically to handle vector embeddings and offer a number of benefits over standalone vector indices.
1. Data management: Well-known and user-friendly functions for storing data, such as adding, removing, and updating data, are provided by vector databases. Compared to using a standalone vector index such as FAISS, which necessitates extra work to integrate with a storage solution, this simplifies the management and maintenance of vector data. Vector databases include the capability to store and filter metadata related to individual vector entries. After that, users can refine their queries by adding more metadata filters to the database.
2. Real-time updates: While standalone vector indexes may need a complete re-indexing procedure to accommodate new data, which can be time-consuming and computationally expensive, vector databases frequently offer real-time data updates, allowing for dynamic changes to the data to keep results current. Index rebuilds can improve speed for advanced vector databases while preserving freshness.
3. Vector databases manage the regular task of backing up all the data kept in the database. This includes collections and backups. Additionally, Pinecone gives users the option to pick and choose which indexes to back up in the form of "collections," which save the data in that index for later use.
4. Ecosystem integration: By making it easier to combine vector databases with other elements of a data processing ecosystem, such as analytics tools like Tableau and Segment, ETL pipelines like Spark, and visualisation platforms like Grafana, the data management workflow can be streamlined. Additionally, it makes it simple to integrate with other AI-related tools like Cohere, LangChain, LlamaIndex, and many more.
5. Data security and access control: To safeguard sensitive data, vector databases usually have built-in data security features and access control methods that standalone vector index solutions might not have. Users can fully divide their indexes and even construct completely isolated partitions within their own index thanks to multi-tenancy via namespaces.
What distinguishes a vector database from a conventional database?
A conventional database assigns values to data points in order to index the data, which is kept in tabular form. A typical database will provide results that precisely match the query when it is queried.
Vectors are stored as embeddings in a vector database, which also allows for vector search, which provides query results based on similarity metrics instead of exact matches. Where a standard database "falls short," a vector database "steps up": Its functionality with vector embeddings is by design.
Due to its scalability, flexibility, and ability to support high-dimensional search and customizable indexing, vector databases are also preferable to standard databases in certain applications, including similarity search, AI, and machine learning applications.
Vector database applications:
Applications for artificial intelligence (AI), machine learning (ML), natural language processing (NLP), and picture identification employ vector databases.
1. Applications for AI/ML: A vector database can enhance AI skills by facilitating long-term memory and semantic information retrieval.
2. Applications of NLP: A vital part of vector databases is vector similarity search, which has applications in natural language processing. A computer may "understand" human, or natural, language by processing text embeddings, which can be done with a vector database.
3. Applications for picture recognition and retrieval: Vector databases convert images into image embeddings. They can find comparable photographs or obtain similar images by using similarity search.
4. Semantic Search: Vector databases have the potential to enhance the effectiveness and precision of semantic searches in information retrieval and natural language processing (NLP). Businesses can utilise vector databases to find comparable words, phrases, or documents by turning text data into vectors using methods like word embeddings or transformers.
5. Identification of Anomalies: The purpose of using vector databases in security and fraud detection is to spot unusual activity. Businesses can utilize similarity search in vector databases to swiftly discover possible threats or fraudulent activities by portraying typical and unusual activity as vectors.
Doing a Vector Database Query:
Let's now explore vector database querying. It may appear intimidating at first, but once you get the feel of it, it's very simple. Using cosine or Euclidean similarity, similarity search is the main technique for querying a vector database.
Here's a basic illustration of how to use a pseudo-code for a similarity search and vector addition:
Import the vector database library
import vector_database_library as vdb
Initialise the vector database
db = vdb.VectorDatabase(dimensions=128)
Add vectors
for i in range(1000): vector = generate*random_vector(128)
generate_random_vector is a function to generate a random 128-dimensional vector
db.add_vector(vector, label=f"vector*{i}")
Perform a similarity search
query_vector = generate_random_vector(128)
similar_vectors = db.search(query_vector, top_k=10)
Upcoming developments in vector databases:
Research on using deep learning to create more potent embeddings for both structured and unstructured data, as well as the advancement of AI and ML, are closely related to the future of vector databases1.
As the quality of embeddings is increased, new methods and algorithms are needed for a vector database to handle and analyse these embeddings more effectively. Actually, new approaches of this kind are constantly being developed.
The creation of hybrid databases is the focus of more research. These aim to address the increasing demand for scalable and efficient databases by fusing the capabilities of vector and classic relational databases.
Conclusion:
Our capacity to traverse and draw conclusions from high-dimensional data environments will be crucial to the success of data-driven decision making in the future. A new era of data retrieval and analytics is thus being ushered in by vector databases. Data engineers are well-suited to tackle the opportunities and problems associated with managing high-dimensional data, spurring innovation across sectors and applications, thanks to their in-depth knowledge of vector databases.
In summary, vector databases are the brains behind these calculations, whether they are used for protein structure comparison, picture recognition, or tailoring the customer journey. They are a vital component of every data engineer's arsenal since they provide a creative means of storing and retrieving data.
navan.ai has a no-code platform - nstudio.navan.ai where users can build computer vision models within minutes without any coding. Developers can sign up for free on nstudio.navan.ai
Want to add Vision AI machine vision to your business? Reach us on https://navan.ai/contact-us for a free consultation.